Vision Transformers
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Draw the Vision Transformer model.
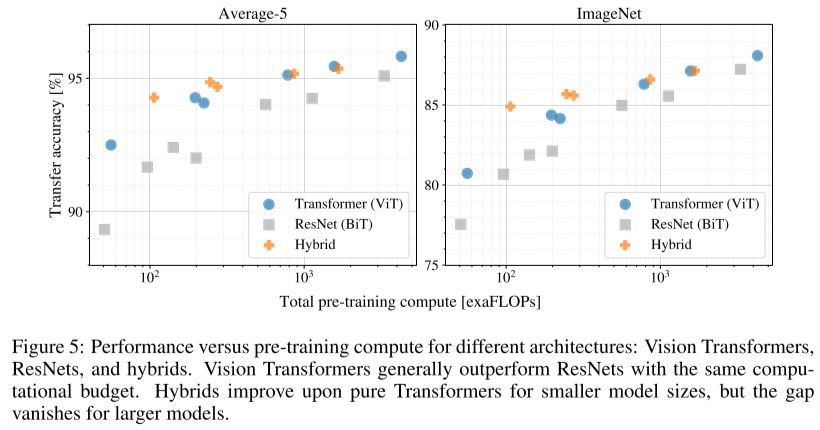
The model design follows the original Transformer (Vaswani et al) as closely as possible.
An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
How is the transformer architecture adapted to make image classification predictions?
Similar to BERT’s [class] token, we prepend a learnable embedding to the sequence of embedded patches (\(\mathbf{z}^0_0 = \mathbf{x}_{\text{class}}\)), whose state at the output of the Transformer encoder (\(\mathbf{z}^0_L\)) serves as the
image representation \(\mathbf{y}\) (Eq. 4). Both during pre-training and fine-tuning, a classification head is attached to \(\mathbf{z}^0_L\). The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
image representation \(\mathbf{y}\) (Eq. 4). Both during pre-training and fine-tuning, a classification head is attached to \(\mathbf{z}^0_L\). The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
What type of positional embeddings are used in Vision Transformers?
Standard learnable 1D position embeddings.
Other embeddings were also tested but they did not observe significant performance gains from using more advanced 2D-aware position embeddings.
Other embeddings were also tested but they did not observe significant performance gains from using more advanced 2D-aware position embeddings.
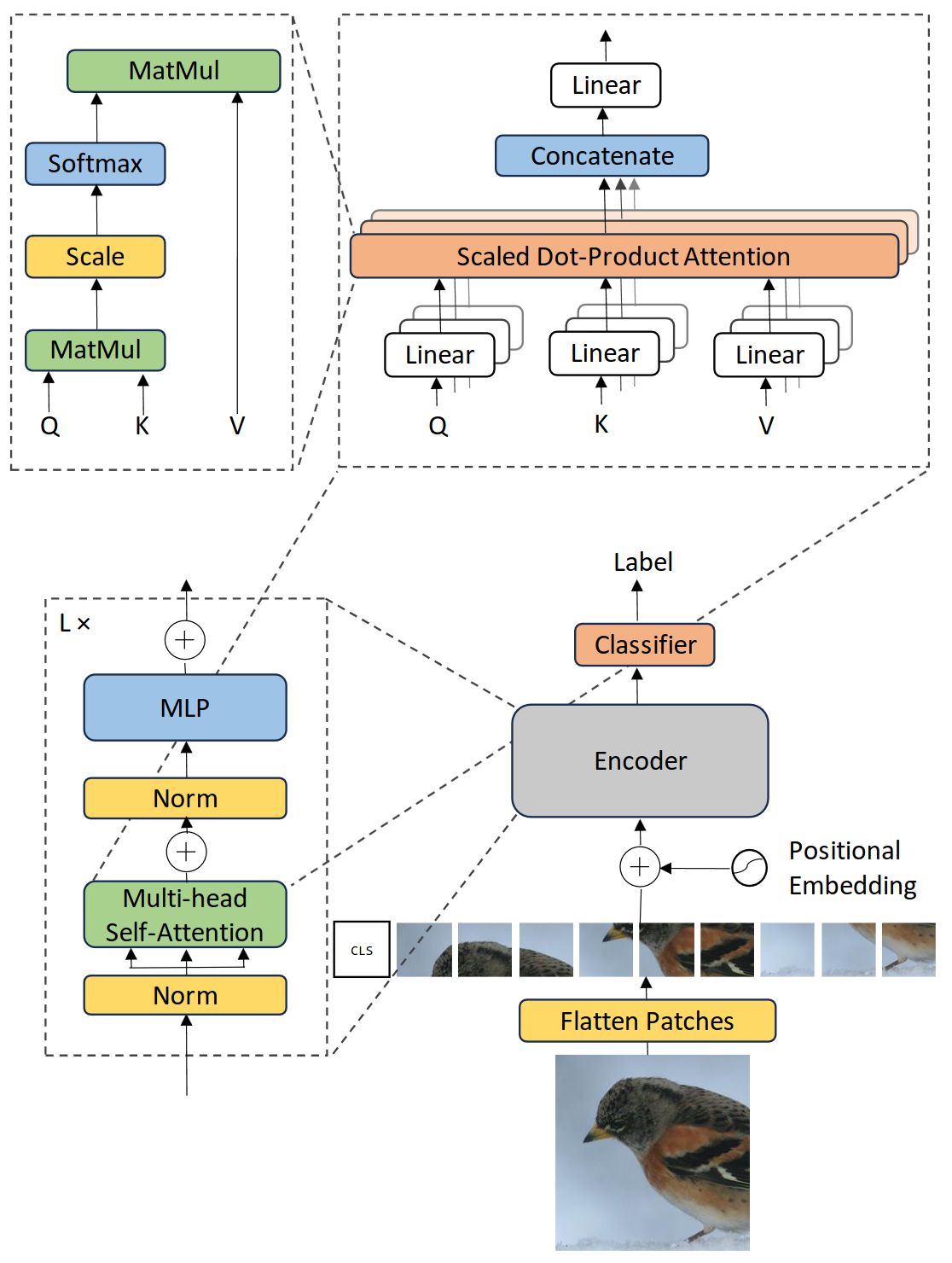
Similarity of position embeddings of ViT-L/32. Tiles show the cosine similarity between the position embedding of the patch with the indicated row and column and the position embeddings of all other patches.
What was the most crucial element to get Transformers to work well in vision?
Dataset size.
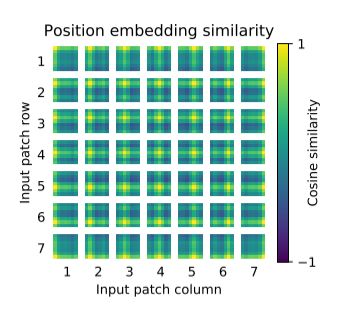
When pre-trained on the smallest dataset, ImageNet, ViTmodels underperform compared to Resnet models. With ImageNet-21k pre-training, their performances are similar. Only
with JFT-300M, do we see the full benefit of the transformer models.
When pre-trained on the smallest dataset, ImageNet, ViTmodels underperform compared to Resnet models. With ImageNet-21k pre-training, their performances are similar. Only
with JFT-300M, do we see the full benefit of the transformer models.
What is a possible explanation to why vision transformers perform worse on small datasets but better on very large datasets?
The intuition is that the convolutional inductive bias is useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is sufficient, even beneficial.
What changes do you need to make to fine-tune ViT?
Remove the pre-trained prediction head and attach a zero-initialized feedforward layer (so one hidden layer instead of 2).
It is often beneficial to fine-tune at higher resolution than pre-training.
When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
It is often beneficial to fine-tune at higher resolution than pre-training.
When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
How many FLOPS and parameters does the ViT model have? And how accurate is it on ImageNet?
ViT-B/16 has 33G FLOPS 86M Params and an ImageNet accuracy of 85.43.
ViT-L/16 has 117G FLOPS 304M Params and an ImageNet accuracy of 85.63.
ViT-L/16 has 117G FLOPS 304M Params and an ImageNet accuracy of 85.63.
The reported accuracies come from the official models when pre-trained on ImageNEt-21k.
How long does it take to pretrain a ViT-L/16 model on the public ImageNet-21k dataset, using standard cloud TPUv3 machines?
240 TPUv3-core-days.
Or 1 month when using 8 cores.
Or 1 month when using 8 cores.
While this does require a lot of compute, Vision Transformers are more efficient to pretrain than ResNet based architectures.