What is a Once-for-all Network?
A once-for-all network is a neural network that can be directly deployed under diverse architecture configurations, amortizing the training cost. Given a deployment scenario, a specialized subnetwork is directly selected from the once-for-all network without training.
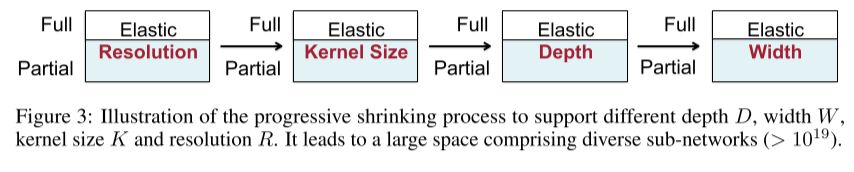
A once-for-all network maintains good accuracy on a large number of sub-networks (more than \(10^{19}\))
Which dimensions are scalable in a once-for-all network?
The depth, width, kernel size, and resolution.
An OFA network is constructed by dividing a CNN model into a sequence of units with gradually reduced feature map size and increased channel numbers.
Each unit is allowed to use arbitrary numbers of layers, each layer to use arbitrary numbers of channels and arbitrary kernel sizes, and the model is also allowed to take arbitrary input image sizes.
Although, arbitrary is maybe a strong word: in their experiments, the input image size ranges from 128 to 224 with a stride 4; the depth of each unit is chosen from {2, 3, 4}; the width expansion ratio in each layer is chosen from {3, 4, 6}; the kernel size is chosen from {3, 5, 7}.
How is a once-for-all network trained?
By using a progessive shrinking training scheme.
Start with training the largest neural network with the maximum kernel size (e.g., 7), depth (e.g., 4), and width (e.g., 6). Next, progressively fine-tune the network to support smaller sub-networks by gradually adding them into the sampling space (larger sub-networks may also be sampled).
Specifically, after training the largest network, first support elastic kernel size, while the depth and width remain the maximum values. Then, support elastic depth and elastic width sequentially. The resolution is elastic throughout the whole training process, which is implemented by sampling different image sizes for each batch of training data. We also use the knowledge distillation technique after training the largest neural network. It combines two loss terms using both the soft labels given by the largest neural network and the real labels.
How are once-for-all networks able to significantly reduce the time for NAS compared to previous work?
They decouple model training from neural architecture search. Or in other words, the search phase does not require any training.
And the training cost is ammortized as many different subnets are trained through a supernet.
And the training cost is ammortized as many different subnets are trained through a supernet.
Starting from a once-for-all network, how do you select a specialized sub-network for a given deployment scenario?
Apart from the OFA network, you also need to construct an accuracy predictor (a small MLP trained on 16K sub-networks and their accuracy measured over 10K validation images) and a latency lookup table.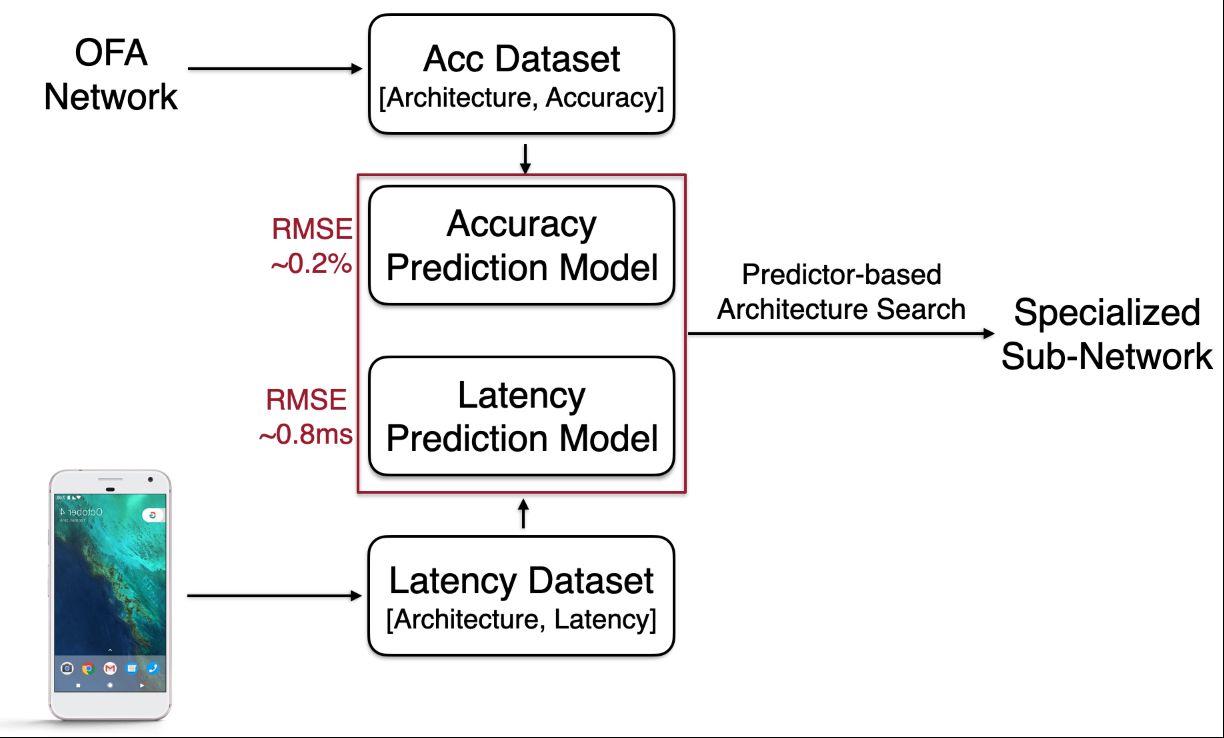
Given the target hardware and latency constraint, you conduct an evolutionary search to get the specialized sub-networks.
Getting the data for the accuracy predictor (i.e. the sub-network and it's accuracy) takes 40 GPU hours.
How many hours does it take to train a once-for-all network (according to the experiments in the paper)?
Around 1,200 GPU hours on V100 GPUs.
+ 40 GPU hours for the accuracy predictor.
How does Elastic Kernel Size work in once-for-all networks?
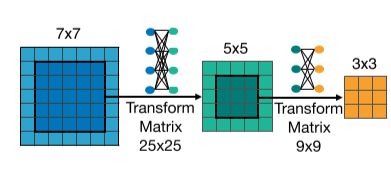
The center of a \(7 \times 7\) convolution kernel also serves as a 5x5 kernel, the center of which also serves to be a 3x3 kernel.
The weights of centered sub-kernels may need to have different distribution or magnitude for different roles. Forcing them to be the same degrades the performance of some sub-networks. Therefore, we introduce kernel transformation matrices when sharing the kernel weights. We use separate kernel transformation matrices for different layers. Within each layer, the kernel transformation matrices are shared among different channels. As such, we only need \(25 \times 25 + 9 \times 9 = 706\) extra parameters to store the kernel transformation matrices in each layer.
How does Elastic Depth work in once-for-all networks?
To derive a sub-network that has D layers in a unit that originally has N layers, we keep the first D layers and skip the last N −D layers.
How does Elastic Width work in once-for-all networks?
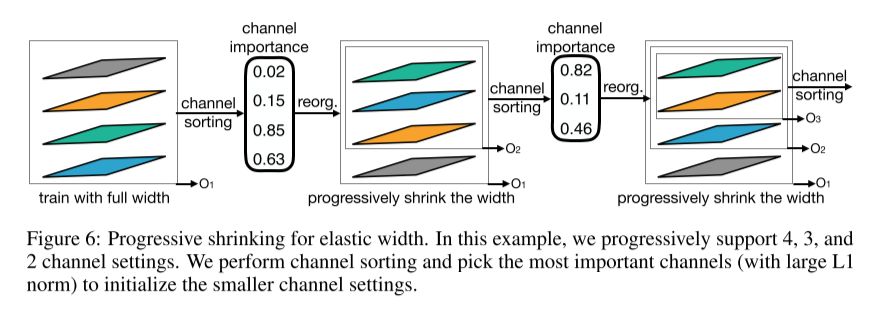
It uses a channel sorting operation which reorganizes the channels according to their importance, which is calculated based on the L1 norm of a channel’s weight.
Thereby, smaller sub-networks are initialized with the most important channels on the once-for-all network which is already well trained. This channel sorting operation preserves the accuracy of larger sub-networks.
How does Elastic Resolution work in once-for-all networks?
The resolution is elastic throughout the whole training process, which is implemented by sampling different image sizes for each batch of training data.