Squeeze-and-Excitation Networks
Draw the structure of a Squeeze-and-Excitation (SE) block.
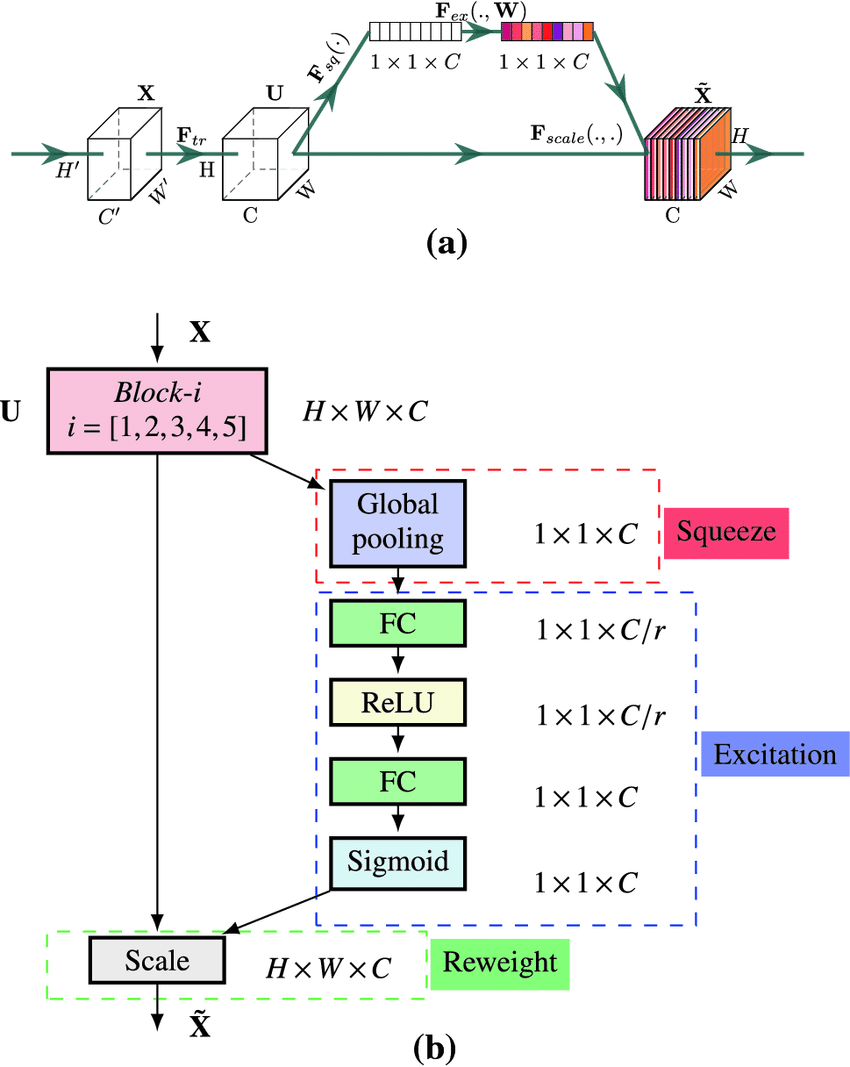
where the pooling operation is a global pooling operator.
A Squeeze-and-Excitation blocks recalibrates the features of a convolutional layer.
The features \(U\) are first passed through a squeeze operation, which aggregates the feature maps across spatial dimensions \(H \times W\) to produce a channel descriptor. This descriptor embeds the global distribution of channel-wise feature responses, enabling information from the global receptive field of the network to be leveraged by its lower layers. This is followed by an excitation operation, in which sample-specific activations, learned for each channel by a self-gating mechanism based on channel dependence, govern the excitation of each channel. The feature maps \(U\) are then reweighted to generate the output of the SE block which can then be fed directly into subsequent layers.
The features \(U\) are first passed through a squeeze operation, which aggregates the feature maps across spatial dimensions \(H \times W\) to produce a channel descriptor. This descriptor embeds the global distribution of channel-wise feature responses, enabling information from the global receptive field of the network to be leveraged by its lower layers. This is followed by an excitation operation, in which sample-specific activations, learned for each channel by a self-gating mechanism based on channel dependence, govern the excitation of each channel. The feature maps \(U\) are then reweighted to generate the output of the SE block which can then be fed directly into subsequent layers.
What is the purpose of the reduction ratio r in Squeeze-and-Excitation layers?
The reduction ratio r is an important hyperparameter which allows to vary the capacity and computational cost of the SE blocks in the model.
The original paper found \(r = 16\) to be a good trade-off while more recent MBConv blocks with an SE module use \(r = 4\)
The original paper found \(r = 16\) to be a good trade-off while more recent MBConv blocks with an SE module use \(r = 4\)
What is the function of Squeeze-and-Excitation blocks?
SE blocks are a mechanism that allows the network to perform feature recalibration, through which it can learn to use global information to selectively emphasise informative features and suppress less useful ones.