Token Merging: Your ViT But Faster
Give the algorithm for Token Merging.
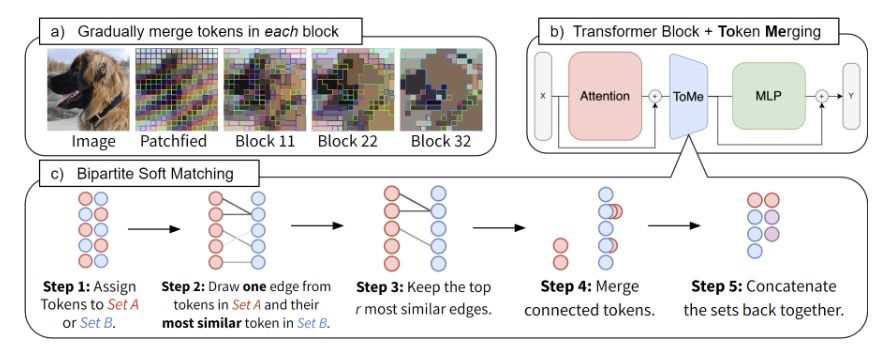
- Partition the tokens into two sets \(\mathbb{A}\) and \(\mathbb{B}\) by alternating the assignment.
- Calculate the similarity score for all tokens in \(\mathbb{A}\) by taking the cosine similarity of the \(\mathbf{K}\) vector of a token in \(\mathbb{A}\) to all tokens in \(\mathbb{B}\). The final similarity score of a token in \(\mathbb{A}\) is the highest pairwise score.
- Merge the \(k\) pairs with the highest similarity score
- Concatenate the two sets back together
Apart from the merging module, which other change needs to be made to the standard Vision Transformer in order to apply Token Merging?
The standard attention function need to be changed to proportional attention:
\[\mathbf{A} = \operatorname{softmax}(\frac{\mathbf{QK}^T}{\sqrt{d}} + \log(\mathbf{s}))\]where \(\mathbf{s}\) is a row vector containing the size of each token (number of patches the token represents). Tokens are also weighted by \(\mathbf{s}\) any time they are aggregated, like when the tokens are merged together.
\[\mathbf{A} = \operatorname{softmax}(\frac{\mathbf{QK}^T}{\sqrt{d}} + \log(\mathbf{s}))\]where \(\mathbf{s}\) is a row vector containing the size of each token (number of patches the token represents). Tokens are also weighted by \(\mathbf{s}\) any time they are aggregated, like when the tokens are merged together.
This performs the same operation as if you'd have s copies of the key
Where is the Token Merging module inserted in the vision transformer?
Between the Multi-headed Self-Attention (MSA) layer and the MLP layer.
What schedule does Token Merging use to merge tokens?
The default setting merges a fixed \(k\) tokens per layer.
They also report on a linearly decreasing schedule.
They also report on a linearly decreasing schedule.