Segment Anything
How long did it take to train the Segment Anything model?
SAM was trained on 256 A100 GPUS for 68 hours. (This is equal to 725 A100 GPU-days)
They acknowledge the environmental impact and cost of training large scale models. The environmental impact of training the released SAM model is approximately 6963 kWh resulting in an estimated 2.8 metric tons of carbon dioxide given the specific data center used. This is equivalent to ∼7k miles driven by the average gasoline-powered passenger vehicle in the US.
What Image encoder is used in the Segment Anything model?
They use an MAE (Masked auto-encoder) pretrained ViT (Vision Transformer).
Specifically a ViT-H/16 with \(14 \times 14\) windowed attention and four equally-spaced global attention blocks.
Following standard practices, they use an input resolution of \(1024 \times 1024\) obtained by rescaling the image and padding the shorter side. The image embedding is therefore \(64\times 64\). To reduce the channel dimension, they use a \(1 \times 1\) convolution to get to 256 channels, followed by a \(3 \times 3\) convolution also with 256 channels. Each convolution is followed by a layer normalization.
Specifically a ViT-H/16 with \(14 \times 14\) windowed attention and four equally-spaced global attention blocks.
Following standard practices, they use an input resolution of \(1024 \times 1024\) obtained by rescaling the image and padding the shorter side. The image embedding is therefore \(64\times 64\). To reduce the channel dimension, they use a \(1 \times 1\) convolution to get to 256 channels, followed by a \(3 \times 3\) convolution also with 256 channels. Each convolution is followed by a layer normalization.
The windowed attention is used to handle high resolution inputs as the window size (i.e. \(14 \times 14\)) matches the full resolution of ImageNet training images.
Give a rough schematic of the Segment Anything Model.
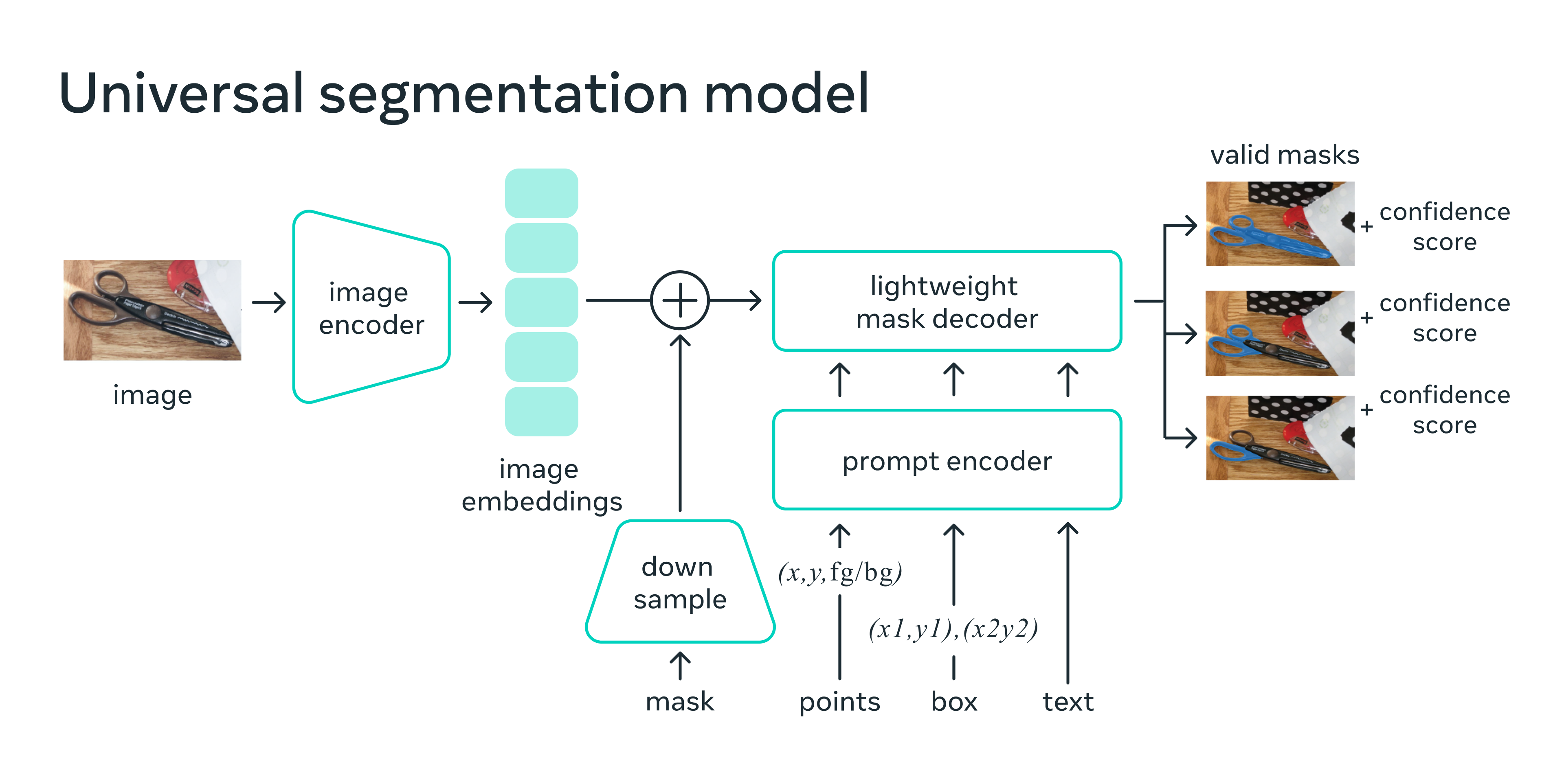
SAM has three components: an image encoder, a flexible prompt encoder, and a fast mask decoder.
Image encoder: an MAE pre-trained Vision Transformer (ViT), minimally adapted to process high resolution inputs.
Prompt encoder: two sets of prompts: sparse (points, boxes, text) and dense (masks). They represent points and boxes by positional encodings summed with learned embeddings for each prompt type and free-form text with an off-the-shelf text encoder from CLIP. Dense
prompts (i.e., masks) are embedded using convolutions and summed element-wise with the image embedding.
Mask decoder: The design employs a modification of a Transformer decoder block followed by a dynamic mask prediction head. The modified decoder block uses prompt self-attention and cross-attention in two directions (prompt-to-image embedding and vice-versa) to update all embeddings. After running two blocks, they upsample the image embedding and an MLP maps the output token to a dynamic linear classifier, which then computes the mask foreground probability at each image location.
What is the architecture of the lightweight mask decoder used in Segment Anything?
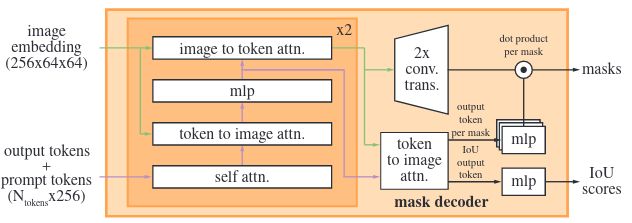
The decoder is a modified Transformer decoder (similar to DETR and MaskFormer).
First insert into the set of prompt embeddings a learned output token embedding that will be used at the decoder’s output, analogous to the [class] token.
For simplicity, we refer to these embeddings (not including the image embedding) collectively as tokens.
Each decoder layer performs 4 steps:
(1) self-attention on the tokens, (2) cross-attention from tokens (as queries) to the image embedding, (3) a point-wise MLP updates each token, and (4) cross-attention from the image embedding (as queries) to tokens.
This last step updates the image embedding with prompt information. During cross-attention, the image embedding is treated as a set of \(64^2\) 256-dimensional vectors. Each self/cross-attention and MLP has a residual connection, layer normalization, and a dropout of 0.1 at training. The next decoder layer takes the updated tokens and the updated image embedding from the previous layer.
They use a two-layer decoder. To ensure the decoder has access to critical geometric information the positional encodings are added to the image embedding whenever they participate in an attention layer. Additionally, the entire original prompt tokens (including
their positional encodings) are re-added to the updated tokens whenever they participate in an attention layer. This allows for a strong dependence on both the prompt token’s geometric location and type.
After the decoder, we upsample the updated image embedding by 4x with two transposed convolutional layers.
Then, the tokens attend once more to the image embedding and we pass the updated output token embedding to a small 3-layer MLP that outputs a vector matching the channel dimension of the upscaled image embedding. Finally, we predict a mask with a spatially point-wise product between the upscaled image embedding and the MLP’s output.
The transformer uses an embedding dimension of 256.
The transformer MLP blocks have a large internal dimension of 2048, but the MLP is applied only to the prompt tokens for which there are relatively few (rarely greater than 20). However, in cross-attention layers where we have a \(64 \times 64\) image embedding, we reduce the channel dimension of the queries, keys, and values by \(2 \times\) to 128 for computational efficiency. All attention layers use 8 heads. The transposed convolutions used to upscale the output image embedding are \(2 \times 2\), stride 2 with output channel dimensions of 64 and 32 and have GELU activations. They are separated by layer normalization.
What is the architecture of the prompt encoder used in Segment Anything?
Sparse (i.e. not the mask) prompts are mapped to 256-dimensional vectorial embeddings as follows.
A point is represented as the sum of a positional encoding of the point’s location and one of two learned embeddings that indicate if the point is either in the foreground or background.
A box is represented by an embedding pair: (1) the positional encoding of its top-left corner summed with a learned embedding representing “top-left corner” and (2) the same structure but using a learned embedding indicating “bottom-right corner”.
For text we use the text encoder from CLIP.
Dense prompts (i.e., masks) have a spatial correspondence with the image. They input masks at a \(4 \times\) lower resolution than the input image, then downscale an additional \(4 \times\) using two \(2 \times 2\), stride-2 convolutions with output channels 4 and 16, respectively. A final \(1 \times 1\) convolution maps the channel dimension to 256. Each layer is separated by GELU activations and layer normalization.
The mask and image embedding are then added element-wise. If there is no mask prompt, a learned embedding representing “no mask” is added to each image embedding location.
A point is represented as the sum of a positional encoding of the point’s location and one of two learned embeddings that indicate if the point is either in the foreground or background.
A box is represented by an embedding pair: (1) the positional encoding of its top-left corner summed with a learned embedding representing “top-left corner” and (2) the same structure but using a learned embedding indicating “bottom-right corner”.
For text we use the text encoder from CLIP.
Dense prompts (i.e., masks) have a spatial correspondence with the image. They input masks at a \(4 \times\) lower resolution than the input image, then downscale an additional \(4 \times\) using two \(2 \times 2\), stride-2 convolutions with output channels 4 and 16, respectively. A final \(1 \times 1\) convolution maps the channel dimension to 256. Each layer is separated by GELU activations and layer normalization.
The mask and image embedding are then added element-wise. If there is no mask prompt, a learned embedding representing “no mask” is added to each image embedding location.
For which task is the Segment Anything Model trained?
The promptable segmentation task, which returns a valid segmentation mask given any prompt. Where a prompt can be a set of foreground / background points, a rough box or mask, free-form text, or, in general, any information indicating what to segment in an image.
The requirement of a “valid” mask simply means that even when a prompt is ambiguous and could refer to multiple objects the output should be a reasonable mask for at least one of those objects.
The requirement of a “valid” mask simply means that even when a prompt is ambiguous and could refer to multiple objects the output should be a reasonable mask for at least one of those objects.
Which losses were used to train Segment Anything?
A linear combination of focal loss and dice loss in a 20:1 ratio of focal loss to dice loss.
How can the Segment Anything model be used for instance segmentation?
It needs to be combined with an object detector which provides the bounding box prompt for Segment Anything.