SETR
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Draw the architecture of the SEgmentation TRansformer (SETR).
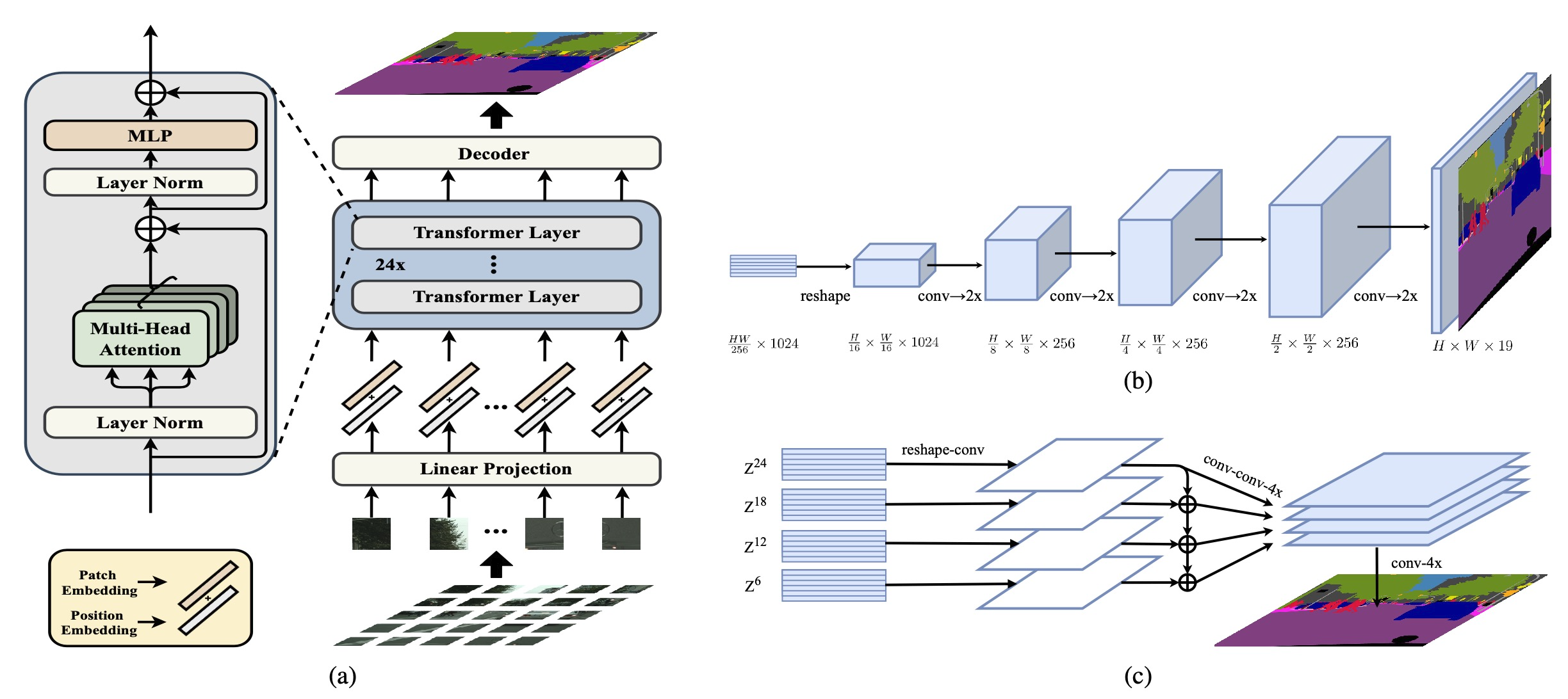
Schematic illustration of the proposed SEgmentation TRansformer (SETR) (a). We first split an image into fixed-size patches, linearly embed each of them, add position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder. To perform pixel-wise segmentation, we introduce different decoder designs: (b) progressive upsampling (resulting in a variant called SETR-PUP); and (c) multi-level feature aggregation (a variant called SETR-MLA).
What is the PUP decoder in SETR?
Progressive UPsampling (PUP)
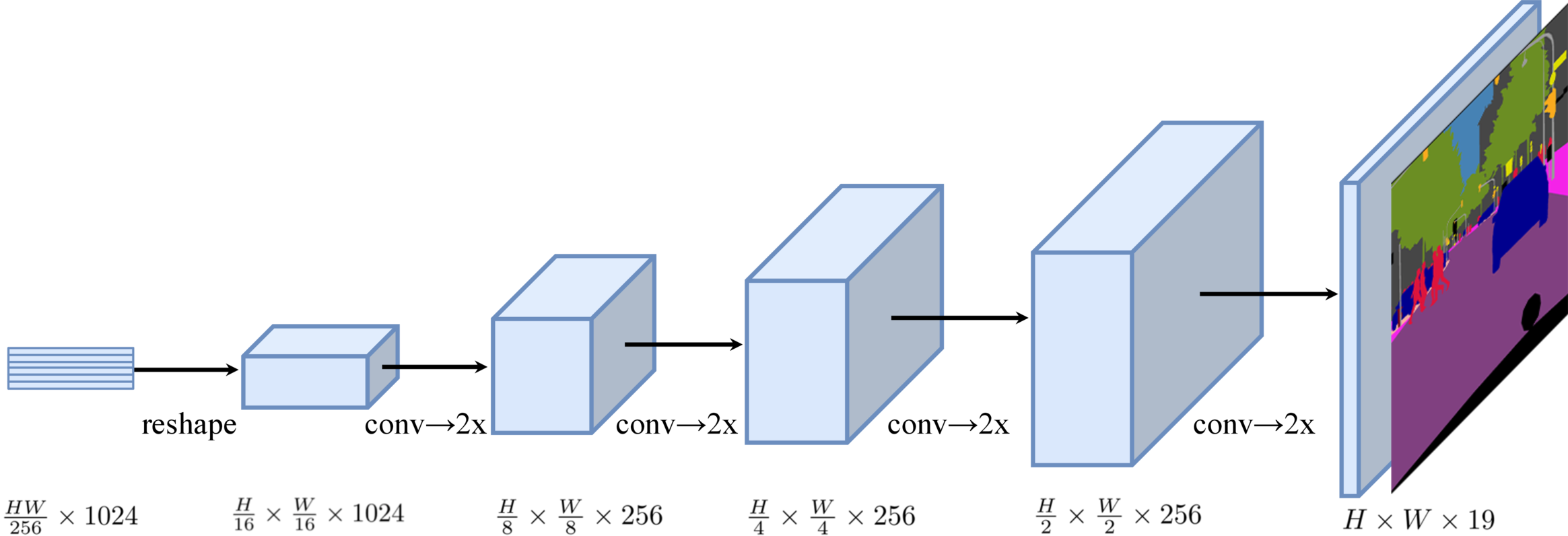
PUP uses a progressive upsampling strategy that alternates conv layers and upsampling operations (upsampling is restricted to \(2 \times\)). Hence a total of 4 operations are needed to reach the full resolution from patches with size \(\frac{H}{16} \frac{W}{16}\). When using this decoder, the models is denoted as SETR-PUP.
What is the MLA decoder in SETR?
Multi-Level feature Aggregation (MLA)
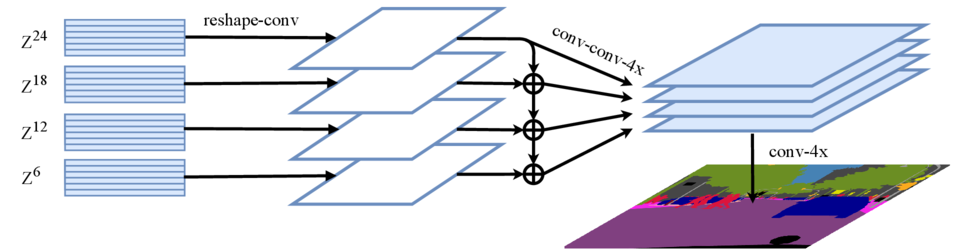
MLA takes as input feature representations \(\{Z^m\} (m \in \{\frac{L_e}{M}, 2\frac{L_e}{M}, ..., M\frac{L_e}{M}\})\) from \(M\) layers uniformly distributed across the layers with step \(\frac{L_e}{M}\) to the decoder. \(M\) streams are then deployed, with each focusing on one specific selected layer.
A 3-layer network is applied with the feature channels halved at the first and third layers respectively, and the spatial resolution upscaled \(4 \times\) by bilinear operation after the third layer. To enhance the interactions across different streams, we introduce a top-down aggregation design via element-wise addition after the first layer. An additional \(3 \times 3\) conv is applied after the element-wise additioned feature. After the third layer, we obtain the fused feature from
all the streams via channel-wise concatenation which is then bilinearly upsampled \(4 \times\) to the full resolution. When using this decoder, we denote our model as SETR-MLA.
A 3-layer network is applied with the feature channels halved at the first and third layers respectively, and the spatial resolution upscaled \(4 \times\) by bilinear operation after the third layer. To enhance the interactions across different streams, we introduce a top-down aggregation design via element-wise addition after the first layer. An additional \(3 \times 3\) conv is applied after the element-wise additioned feature. After the third layer, we obtain the fused feature from
all the streams via channel-wise concatenation which is then bilinearly upsampled \(4 \times\) to the full resolution. When using this decoder, we denote our model as SETR-MLA.