How does LoRA work?
LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture.
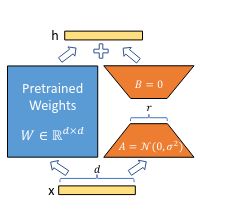
They use a random Gaussian initialization for \(A\) and zero for \(B\), so \(\Delta W = BA\) is zero at the beginning of training.